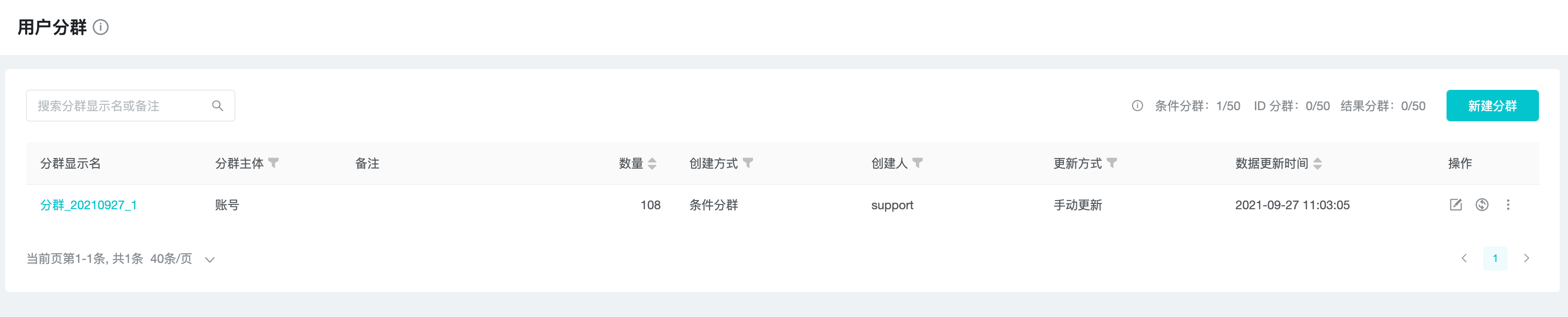
User Clustering
1. Overview
User Clustering is a way to divide users who meet certain properties and behavioral characteristics into a group, and to study and analyze the group.
In the analysis model of TapDB, "account" and "device" are used as query subjects, and "account" and "device" are also supported as subjects in user clustering.
Currently, we support 3 types of user clustering: "Conditional Clustering", "ID Clustering" and "Result Clustering".
2. Applicable Scene
| Roles | Usage |
|---|---|
| Analyst/business person | Segmenting specific user groups for focused analysis, troubleshooting, or exporting user lists, etc. |
3. Creating User Clustering
3.1 Conditional Clustering
Select "New sub-group" and "New Condition group" in the upper right corner of the subgroup page. Please pay attention to the progress here.
This page is divided into two parts: "basic information" and "Group rules".
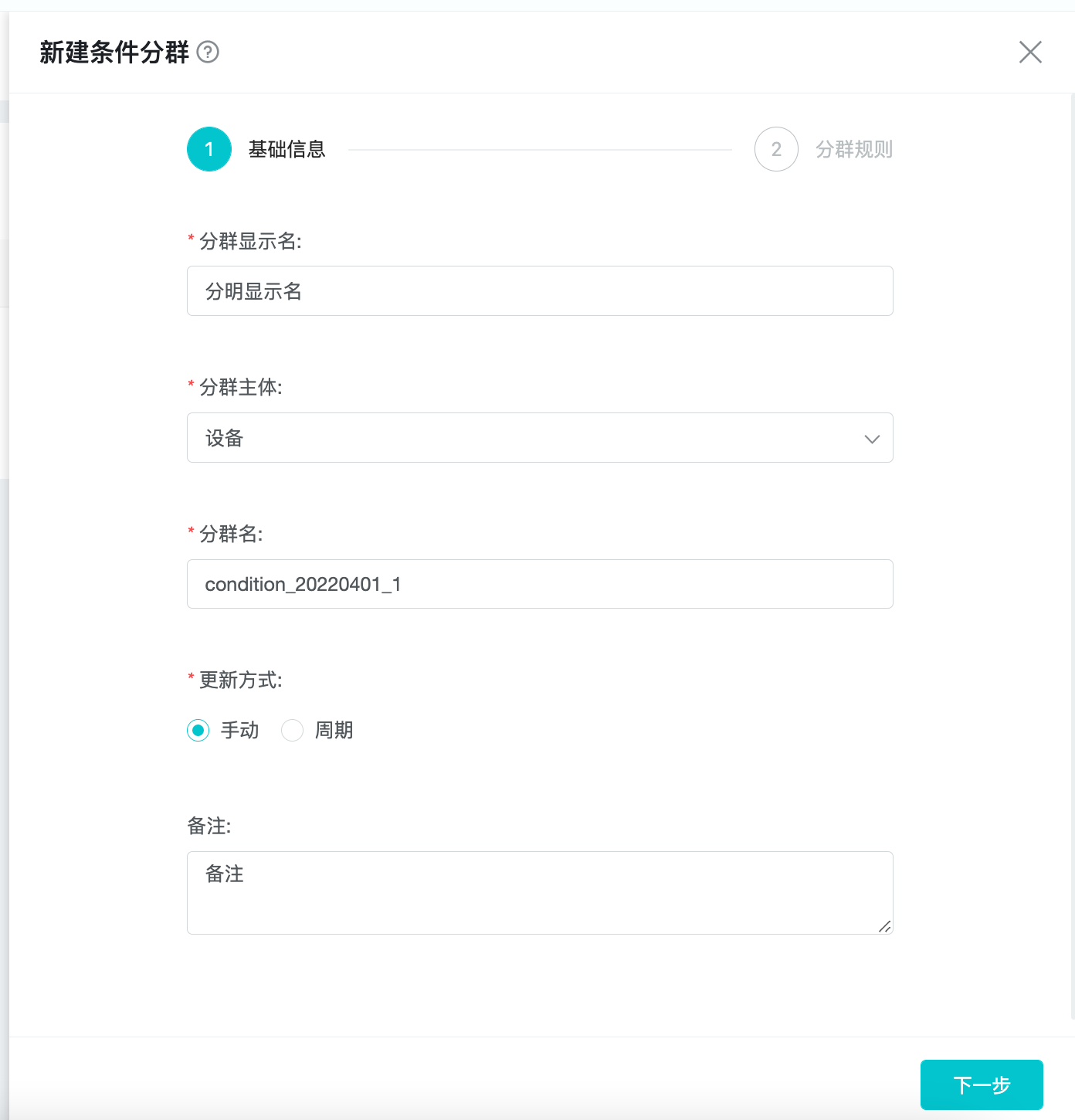
On the "basic information" page, enter or select "Group display name, Group, Group name, Update method, and Remark" in order.
Group display name: displayed in the group list and analysis page, which is the basis for business personnel to identify subgroups.
Group: support "account" or "device", choose according to the business scenario.
Group name: It is the unique identification of the subgroup stored in the system background, and can be named as the parameter name with business meaning for the convenience of data analysts to query the database table directly.
The update method is divided into "Manually" and "cycle". "Manually" means that the system will not automatically update the user group after the first calculation is completed, and users need to update manually; "cycle" means that the system will update the user group after 0:00 every day, taking the previous day as the base, and you can set the update delay to ensure that all the data of the previous day are received to ensure data integrity.
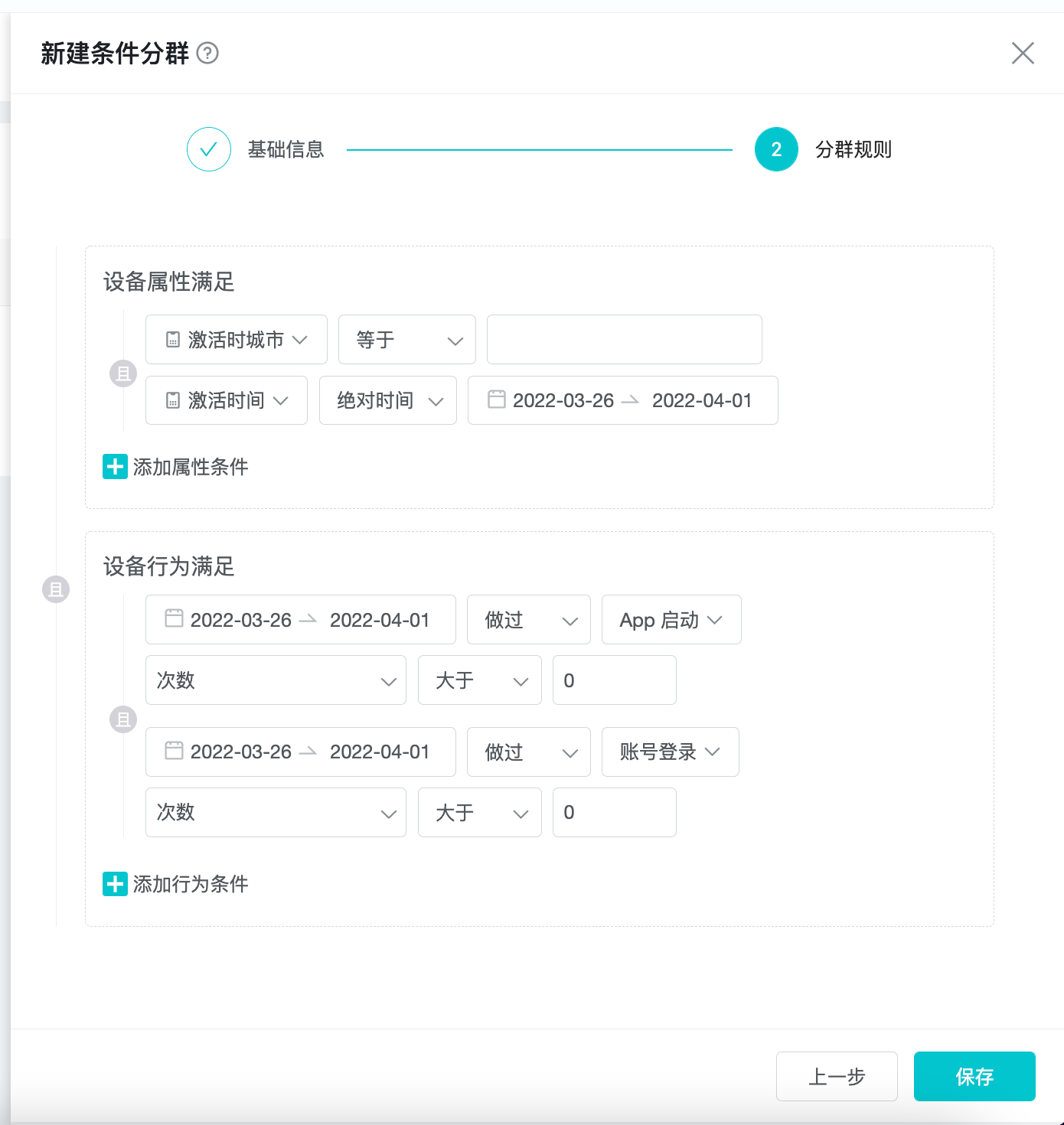
In the "Group Rules" page, the rules are divided into two parts: "User attribute satisfaction" and "User behavior satisfaction", and you can switch the "and or" relationship between the two parts.
In the "User behavior satisfaction" section, the attribute conditions are set based on the selected subgroup subject, and each attribute condition can switch the "and or" relationship.
In the "User behavior satisfaction" section, it can be divided into two categories: "Never done event" and "done event", and both conditions can be added multiple times.
"Never done event" means that the user has not done the behavior in the selected time period.
"Done event" means that the user has done the behavior in the selected event period, and the results of the behavior can be filtered.
3.2 ID Clustering
Select "New sub-group" and "Upload ID group" in the upper right corner of the subgroup page.
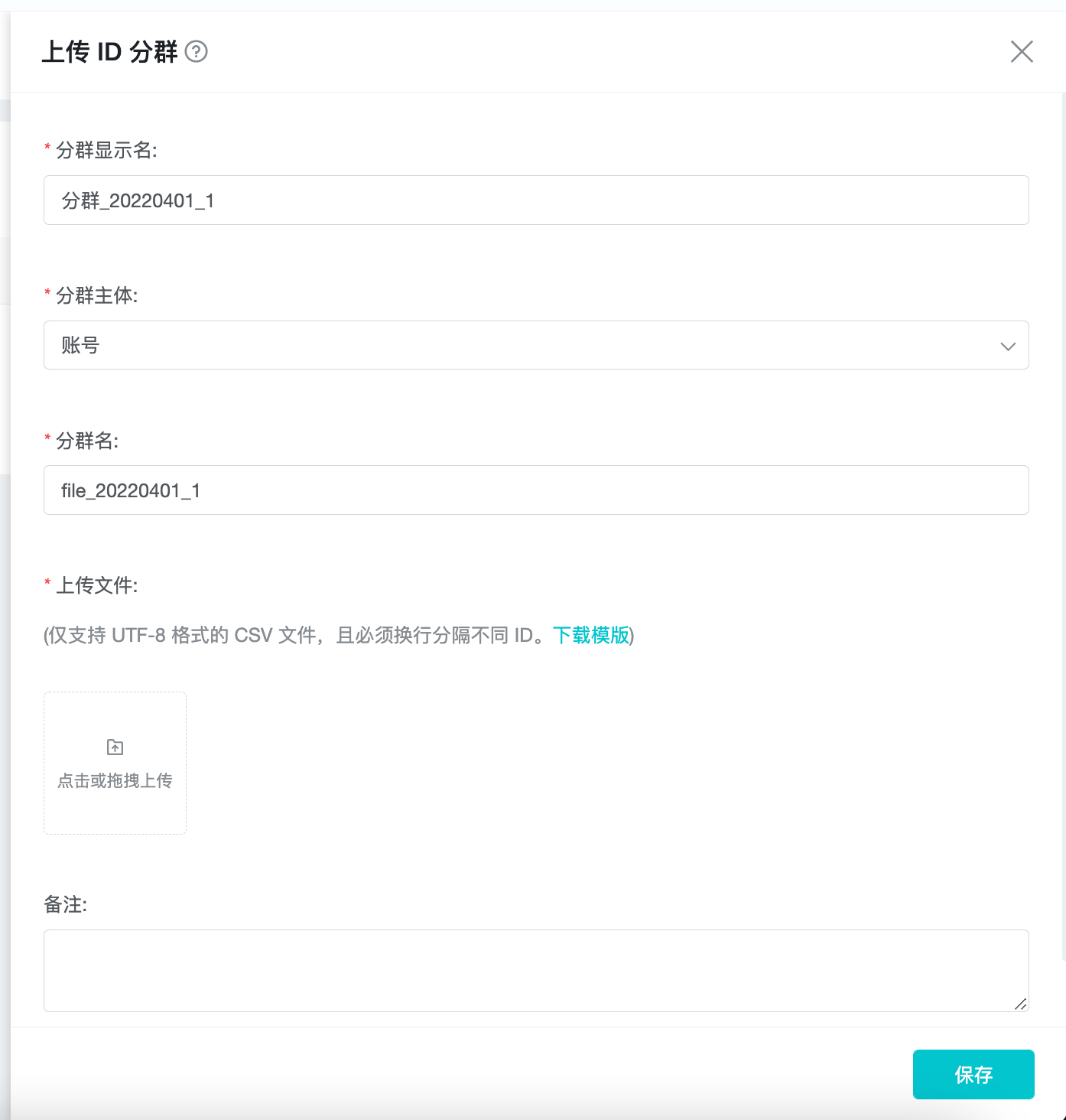
Upload the ID file on the current page, and the system will correlate the IDs in the file with the existing user data in the system according to the selected "group subject" to find the eligible users.
File format requirements: one ID per line, CSV file encoded in UTF-8 format. If there is an unmatched item in the upload (i.e. a user with this ID does not exist in the project), the item will be skipped and will not be included in the group. The template can be downloaded as a reference.
3.3 Result Clustering
In each analysis model, if the indicator is the number of users (e.g. "number of triggered users" in event analysis, retained or churned users in a segment of retention or funnel analysis), you can create groups by clicking "New result groups" in the result report.
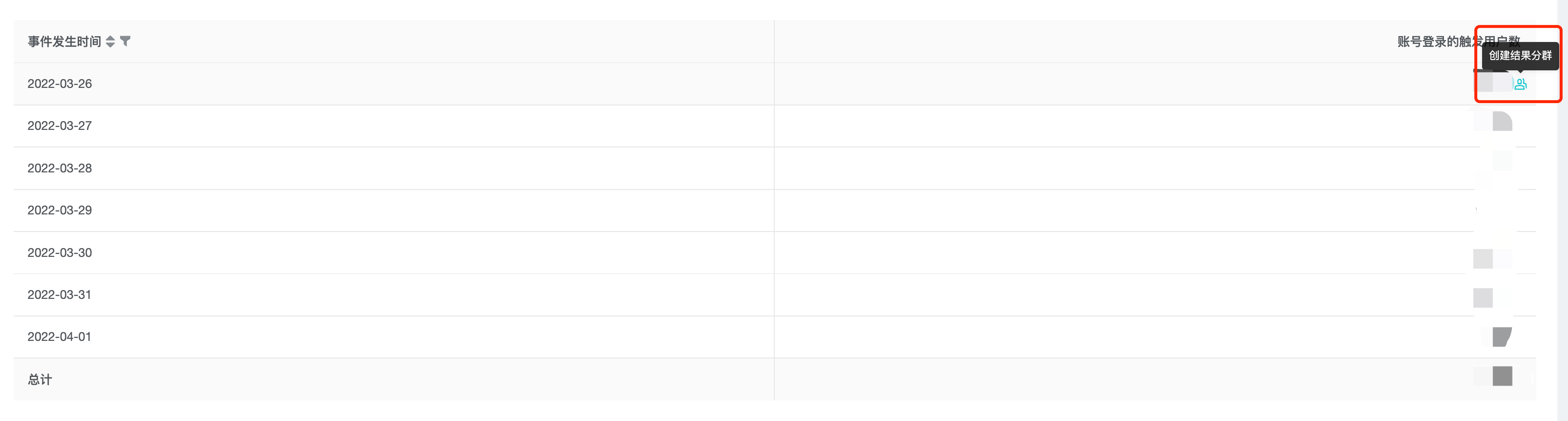
You can set the name and remark of the resulting group.
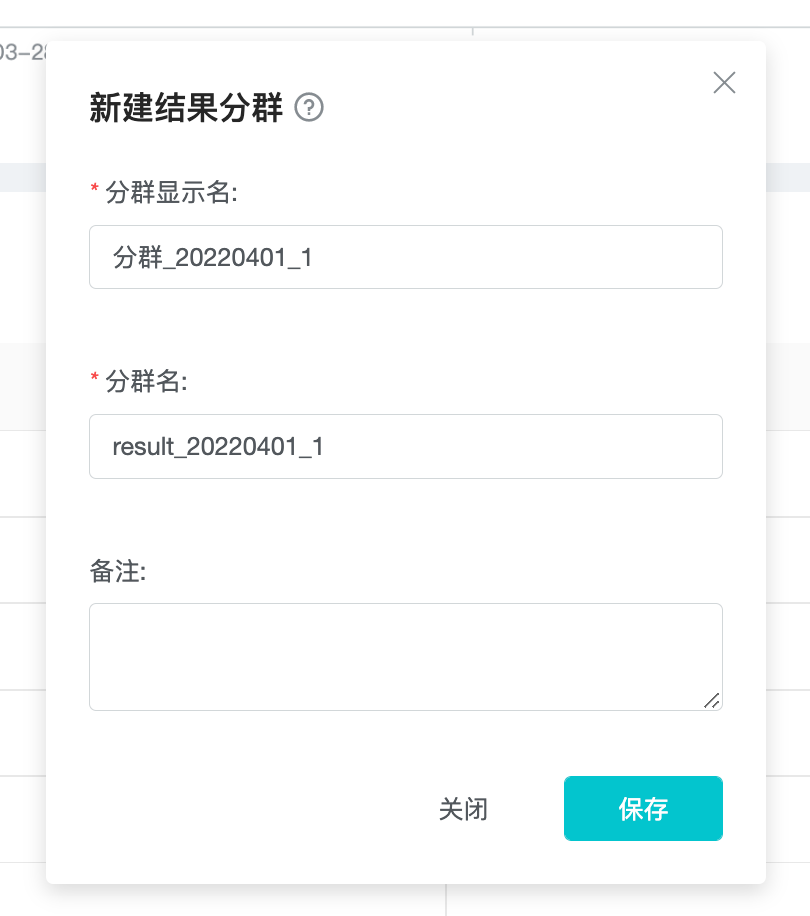
You can't modify and update the rules of resulting group, you can only modify the name and remark.
4. Various Operations
The created clusters are displayed as a list on the user clustering page.

Users can view, edit, delete, update, download, and copy operations on the cluster, as follows.
| Operation | Location | Effect |
|---|---|---|
| View | Name | View cluster Details |
| Edit | Action bar | Enter the Edit cluster popup |
| Delete | Action Bar | Delete cluster |
| Update | Action bar | Manually start the cluster calculation and update the cluster results |
| Download | Action bar | Download the list of users with the current cluster results |
| Copy | Action bar | Create a new cluster with the same parameters as the current one |
5. Using User Clustering
5.1 Focusing or excluding some users
Focusing on high-value users who meet certain criteria, such as: those who pay more than $100, so as to target strong paying users in the analysis model and understand their behavioral characteristics.
Excluding suspicious users that meet specific conditions, such as: devices that have been active on the same device for more than 3 accounts, you can exclude such studio devices without affecting the analysis results of normal users.
5.2 User data import and export
Import external user data into the system to create cluster, such as: the company already has a group of users and devices with high paying ability in other game projects, so it can be imported to explore their active and paying situation in this project and better guide potential high paying users to pay.
Download the cluster results as the basis of operation in other systems, such as: exporting suspected studio devices, accounts, and then punishing and banning them in the game operation system.
5.3 The analysis results of the drill-down analysis
The result cluster is based on the report of the analytic model and is therefore well suited as a basis for drill-down analysis.
For example, the funnel analysis calculates the funnel conversion of users browsing products, initiating orders, and paying for orders, and finds that a large number of users are lost after initiating orders. In this case, the result cluster of the lost users can be analyzed to explore the reasons why they initiated orders but did not pay successfully by analyzing the attributes and behaviors.